23.07.2025
Qualität bewerten: Automatisierte MT-Evaluation in der Praxis
Der Einsatz maschineller Übersetzung ist in vielen Unternehmen längst verankert, doch eine Routine zur Bewertung der Qualität gibt es oftmals nicht. Dabei lohnt sich nicht nur eine initiale Qualitätsprüfung zur Systemauswahl, sondern auch eine fortlaufende Beobachtung, um Qualitätsveränderungen frühzeitig zu erkennen. Die menschliche Begutachtung großer Mengen maschinell übersetzter Inhalte in diversen Zielsprachen ist allerdings für die meisten Unternehmen weder wirtschaftlich noch personell umsetzbar. Maschinelle Metriken zur automatisierten Evaluation von MT-Systemen versprechen hier Abhilfe. Wir zeigen Ihnen, wie sie funktionieren, was sie leisten, und warum der Mensch im Prozess trotzdem unabdingbar bleibt.
Gemeinsamkeiten und Unterschiede: Quality Evaluation und Quality Estimation
Wer schon einmal in einer neuen Stadt auf der Suche nach einem potentiellen Lieblingsrestaurant war, weiß, wie schwierig ein solches Unterfangen sein kann. Online-Bewertungen bieten oft einen ersten Anhaltspunkt und sortieren vor, wo man gut essen kann. Über Filtermöglichkeiten lassen sich die Suchergebnisse auch eingrenzen. Und doch bleiben viele der eigenen Präferenzen am Ende unberücksichtigt, sodass das eigene Austesten neuer Restaurants notwendig bleibt. Mit der Bewertung von MT-Systemen verhält es sich im Grunde ganz ähnlich: Automatisierte Metriken geben Ihnen erste wichtige Hinweise darauf, wo Sie die Qualität Ihrer maschinellen Übersetzungen kritisch hinterfragen sollten. Sie basieren ihre Entscheidung allerdings nur auf einfachen allgemeinen Kriterien, wie Vollständigkeit und inhaltliche und formale Übereinstimmung mit einer Referenz.
Bei der automatisierten Evaluation von MT-Systemen (auch Quality Evaluation genannt) wird ein Vergleich angestellt zwischen der maschinellen Rohübersetzung und einer „Referenz“, das heißt einer hochwertigen geprüften Übersetzung des gleichen Textes. Diese bildet den Standard, dem sich das maschinelle Übersetzungsergebnis annähern soll. Quality Evaluation unterscheidet sich somit von der Quality Estimation, die maschinelle Übersetzungen ohne Verwendung eines Referenztexts bewertet. Quality Estimation kommt vor allem im laufenden Übersetzungsprozess zum Einsatz, wo die Bewertung pro Segment als Indikator dafür dienen soll, welche Segmente ein Posteditieren erfordern. Wie zuverlässig diese Bewertung ist, hängt massiv vom eingesetzten Quality-Estimation-Modell ab.
Die Qualitätsevaluation hingegen dient der Einschätzung der durchschnittlichen Qualität eines MT-Systems über viele übersetzte Segmente hinweg. Da sie eine Referenzübersetzung benötigt, findet sie im Nachgang zu MTPE-Projekten statt.
Aus dem Ergebnis einer Evaluation können Maßnahmen zur Verbesserung des maschinellen Rohergebnisses abgeleitet werden, zum Beispiel durch übersetzungsgerechtes Anpassen der Ausgangstexte. Wird die Evaluation vergleichend auf den Output mehrerer MT-Systeme angewendet, kann sie auch die Entscheidung unterstützen, welches der MT-Systeme für die jeweilige Sprache und Textsorte besser geeignet ist.
Wie automatisierte Metriken wirklich funktionieren
Online-Restaurantbewertungen mit enthusiastischen 5 von 5 Sternen ebenso wie jene mit nur einem Stern wecken bei vielen von uns Neugierde zu erfahren, worauf diese Bewertung fußt. Schlägt sich in der 1-Stern-Bewertung zum Beispiel nur Frustrationen über die lauten Tischnachbarn nieder, so sagt das wenig über die Qualität des Essens aus. Erhalten wir bei der Evaluation von MT-Systemen wiederum einen Wert von 0,82 auf einer Skala von 0 bis 1, so ist auch das zunächst einmal eine Blackbox. Zeit also, zu verstehen, woraus sich die Bewertung errechnet.
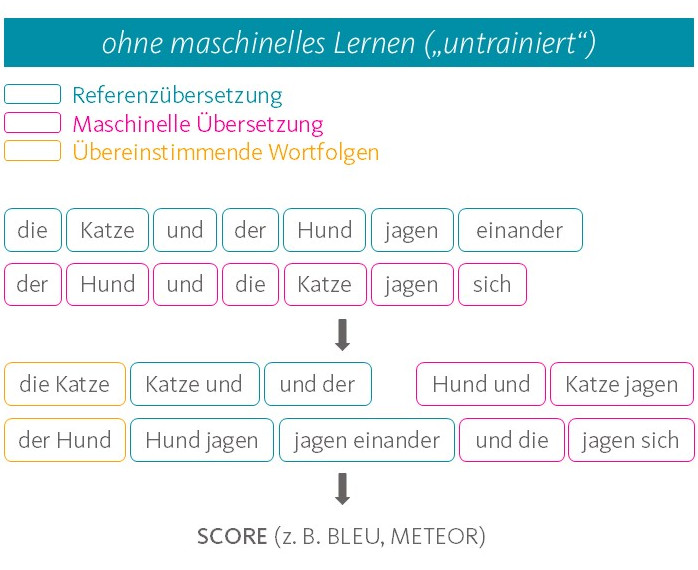
Während der automatisierten Evaluation wird für jedes Segment innerhalb des Textes ein numerischer Wert errechnet, der angeben soll, wie gut – also wie nahe an der Referenz – die maschinelle Übersetzung ist. Außerdem erhält man einen Gesamtwert aus dem Durchschnitt der Segmentbewertungen. Erst ein Blick auf die zugrundeliegenden Algorithmen liefert Informationen darüber, woraus sich die Segmentbewertungen zusammensetzen und wo die Limitationen automatisierter Evaluationsmetriken liegen. Die eingesetzten Algorithmen lassen sich dabei grob in zwei Typen unterteilen, gemessen daran, ob sie die Texte mit oder ohne künstliche neuronale Sprachmodelle verarbeiten: Beginnen wir mit dem einfacheren Typ der Evaluationsmetrik, deren populärster Vertreter die Metrik BLEU ist. Sie arbeitet relativ simpel und unterteilt die Texte lediglich in ihre Worteinheiten und vergleicht auf dieser Basis, ob der MT-Output und die Referenzübersetzung die gleichen Worte, wenn möglich gar in gleicher Reihenfolge, enthalten. Je größer die Übereinstimmung, desto besser das Ergebnis. Die Bedeutung der Einzelworte sowie des daraus geformten Satzes werden aber nicht berücksichtigt. Umformulierungen durch Verwendung von Synonymen oder einer anderen Satzstruktur werden somit abgestraft, obwohl derartige Unterschiede zwischen unabhängig voneinander erzeugten Übersetzungen absolut üblich sind.
Anspruchsvollere Metriken nutzen hingegen künstliche neuronale Sprachmodelle, die die Texte zunächst in ein numerisches Repräsentationsformat übertragen, anhand dessen MT-Output und Referenz im Anschluss verglichen werden. Der Vorteil: neuronale Sprachmodelle repräsentieren die Wort- und Satzbedeutung als multidimensionale Vektoren, wodurch ähnliche Bedeutungen sich in ähnlichen Vektoren niederschlagen. Die Verwendung von Synonymen und Variationen der Satzstruktur werden so abgefangen. Zur Bewertung des MT-Outputs wird die Ähnlichkeit zwischen den relevanten Vektoren bestimmt. Je größer die Ähnlichkeit, desto besser die Bewertung des MT-Outputs in Evaluationsmetriken wie BERTscore.
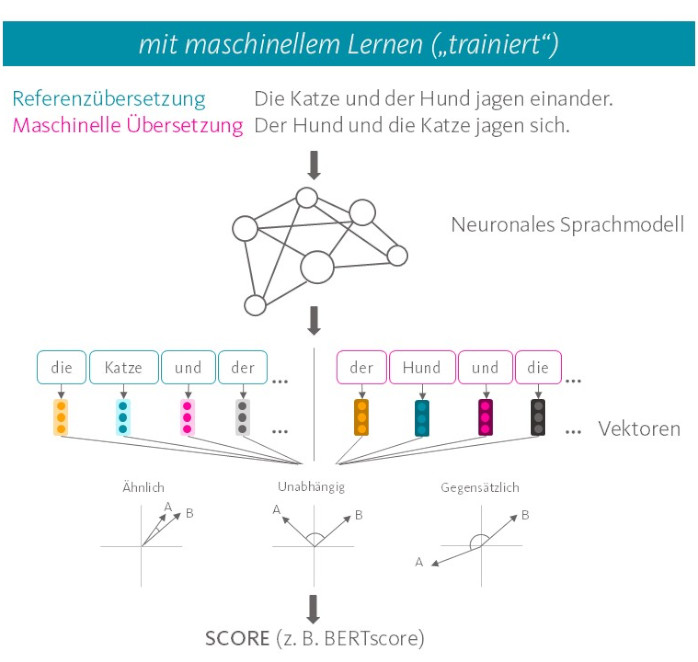
Etwas komplizierter gestaltet es noch die Evaluationsmetrik COMET, die nach der initialen Verarbeitung im neuronalen Sprachmodell ein zweites neuronales Netzwerk nutzt, um die Bewertung des MT-Outputs vorzunehmen. Dieses Netzwerk wurde anhand von menschlichen Bewertungen maschineller Übersetzungen darauf trainiert, vorherzusagen, wie Menschen den jeweils vorliegenden MT-Output bewerten würden. So soll COMET eine höhere Korrelation mit menschlichen Bewertungen von MT-Ergebnissen erzielen.
Zusammengefasst können automatisierte Evaluationsmetriken durch einen Abgleich zwischen MT-Output und Referenzübersetzung vor allem inhaltliche Unterschiede aufdecken. Grobe Abweichungen, wie Auslassungen und Ergänzungen sowie Übersetzungsergebnisse, die nicht sinngenau sind, können anhand der eingesetzten Algorithmen erkannt werden. Doch wie sieht es mit weiteren Qualitätskriterien aus?
Limitationen und Nutzen in der Praxis
Bei oneword setzen wir bewusst nicht auf vollautomatisierte Evaluation, sondern auf den direkten Austausch mit den Posteditor:innen. Nach jedem MTPE-Projekt erfolgt ein obligatorisches Feedback zum MT-Output. Dieses erfasst in zehn Kategorien Fehlerquellen wie Vollständigkeit, Rechtschreibung und Grammatik. Die Ergebnisse zeigen: während eine korrekte Rechtschreibung, Grammatik und ein vollständiges Ergebnis oft gegeben sind, treten insbesondere bei Terminologie, Formatierung und interner Konsistenz oft Fehler im maschinellen Ergebnis auf, die eine menschliche Nachbearbeitung durch Post-Editing unerlässlich machen.
Ein Knackpunkt der automatisierten Evaluation von MT-Systemen ist allerdings, dass insbesondere Terminologie und interne Konsistenz nicht korrekt abgeprüft werden. Keine der Evaluationsmetriken ist in der Lage, Unternehmensvorgaben, wie sie in einer Terminologiedatenbank oder in einem Styleguide vorliegen, zu berücksichtigen. Allenfalls werden Metriken Terminologiefehler als Abzüge für Wortunterschiede registrieren, sofern im MT-Output eine andere Benennung als in der Referenzübersetzung verwendet wurde. Ebenso kritisch: Da die Metriken auf Segmentebene bewerten, bleiben Inkonsistenzen zwischen den Segmenten komplett unberücksichtigt.
Fazit: Investition mit hohem Benefit
Angesichts dieser Limitationen wird klar, dass eine menschliche Bewertung unabdinglich bleibt, um die teils subtilen Faktoren zu erfassen, die die Qualität eines Textes ausmachen. Automatisierte Evaluationen von MT-Systemen sollten daher nicht alleinstehend angewandt werden. Dennoch bleibt der Nutzen für bessere MT-Ergebnisse enorm hoch. Eine automatisierte Evaluation kann insbesondere dann wichtige erste Eindrücke zur Qualität eines MT-Systems liefern, wenn sie über große Textmengen angewandt wird, die im Nachhinein stichprobenhaft untersucht werden. Die menschliche Prüfung, vor allem der besonders positiv oder negativ bewerten Segmente, liefert im Nachgang Aufschluss über die Fehlerquellen im MT-Output und die Zuverlässigkeit der Evaluationsmetrik. So können die Ergebnisse die Wahl zwischen zwei MT-Systemen oder auch die Entscheidung für oder gegen den Einsatz maschineller Übersetzung ganz allgemein unterstützen. Es bleibt also wie bei der Suche nach einem guten Restaurant: Niemand kennt die eigenen Ansprüche besser als man selbst!
Sie möchten die Qualität Ihres MT-Systems professionell bewerten lassen? Oder Sie suchen nach der optimalen Kombination aus automatisierter Evaluation und menschlicher Expertise?
Sprechen Sie uns an – wir unterstützen Sie dabei, das Maximum aus Ihrer maschinellen Übersetzung herauszuholen und dabei wirtschaftlich zu arbeiten. Mit unserer oneSuite und unserem langjährigen Know-how in maschineller und KI-gestützter Übersetzung finden wir gemeinsam die beste Lösung für Ihre Anforderungen. Nehmen Sie noch heute Kontakt mit uns auf.
8 gute Gründe für oneword.
Erfahren Sie mehr über unsere Kompetenzen und was uns von klassischen Übersetzungsagenturen unterscheidet.
Wir liefern Ihnen 8 gute Gründe und noch viele weitere Argumente, warum eine Zusammenarbeit mit uns erfolgreich ist.