25.06.2025
Terminologiedatenbank: In 5 Stufen vom Wildwuchs zum Wortschatz
Eine gut gepflegte Terminologiedatenbank ist das Fundament konsistenter und kosteneffizienter Unternehmenskommunikation. Doch in der Praxis zeigt sich oft ein anderes Bild: Über Jahre gewachsene Bestände, zusammengeführte Listen aus unterschiedlichen Abteilungen und uneinheitliche oder fehlende Standards führen zu einem schwer nutzbaren Datenwildwuchs. Eine systematische Bereinigung dieser Datenbestände zahlt sich somit direkt in Zeit- und Kostenersparnissen bei Texterstellung, Übersetzung und Kommunikation aus.
Die Herausforderung: Durcheinander in Terminologiedatenbanken
Terminologieverwaltung nimmt eine Schlüsselposition im Unternehmen ein, denn eine gepflegte Terminologiedatenbank stellt die konsistente Verwendung von Fachtermini über alle Abteilungen, Dokumente und Sprachen hinweg sicher. Sie dient als zentrale Referenz für die Texterstellung, wird in Autorensystemen und Übersetzungstools eingebunden und bildet die Grundlage für qualitativ hochwertige maschinelle Übersetzungen.
Sobald jedoch mit dem Terminologiemanagement begonnen wird, entwickelt sich häufig eine ausgeprägte Sammelleidenschaft. Unterschiedlichste Bestände werden zusammengeführt, neue Termini aus Dokumenten extrahiert und bei Produktentwicklungen festgelegt. Das Ergebnis: ein unkontrollierter Wildwuchs, besonders wenn Standards erst spät im Prozess etabliert werden.
Vier Hauptgründe führen zu unsauberen Terminologiedaten:
- Datenbestand nimmt Überhand: Die Sammlung der Sprachdaten wächst kontinuierlich an.
- Fehlende Bereinigungsroutinen: Der Sammelleidenschaft steht keine regelmäßige Prüfung und Bereinigung gegenüber.
- Uneinheitliche Vorgehensweisen: Für die Befüllung und Pflege gibt es keine einheitlichen Standards.
- Mehrere Bearbeiter:innen: Verschiedene Personen, Abteilungen oder Dienstleister bearbeiten die Datenbank, wodurch der Überblick verloren gehen kann.
Der 5-Stufen-Ansatz zur systematischen Bereinigung
Um diesen Gründen entgegenzuwirken, sollte die Bereinigung einer Terminologiedatenbank strukturiert erfolgen. Dabei hat sich ein trichterförmiges Vorgehen bewährt, bei dem zunächst die Menge in Form von offensichtlich überflüssigen Einträgen reduziert wird, bevor Details bearbeitet werden.
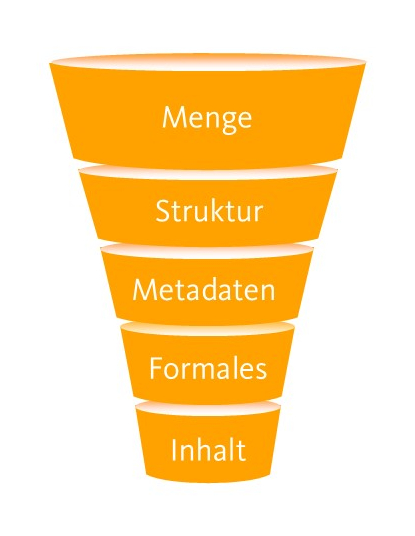
Trichterförmiges Vorgehen bei der Terminologiebereinigung von oben nach unten (Quelle: oneword GmbH)
Stufe 1: Mengenreduzierung durch Bestandsanalyse
Der erste und wichtigste Schritt betrifft also die Anzahl der Einträge. Analysen aus unseren eigenen Projekten zeigen: Teilweise enthalten Datenbanken nur 20 bis 30 Prozent aktive Terminologie. Besonders bei umfangreichen Beständen mit über 5.000 Einträgen ist der Anteil inaktiver Terminologie oft erschreckend hoch.
Daher ist es sinnvoll, den aktiven Datenbankanteil mithilfe einer Bestandsanalyse zu ermitteln. Das Ziel dieser Analyse ist es, die tatsächlich verwendete von der ungenutzten Terminologie zu trennen. Dafür gleichen wir Ihren Terminologiebestand mit aktuellen Unternehmenstexten ab – zum Beispiel mit Dokumentensammlungen aus verschiedenen Bereichen und Abteilungen oder mit Translation Memorys. Für jeden Terminus aus der Datenbank wird geprüft, ob und wie häufig er in den Referenztexten vorkommt. Die Analyse zeigt nicht nur, welche Termini aktiv genutzt werden, sondern ermöglicht aufgrund der Ermittlung der Häufigkeit auch eine Priorisierung des Bestands für Folgeschritte wie Definitions- oder Glossarerstellungen.
Bei kleinen Beständen kann diese Analyse manuell oder per Suchfunktion durchgeführt werden. Umfangreiche Datenbanken sollten jedoch skriptbasiert analysiert werden. Das Ergebnis liefert im Umkehrschluss auch die inaktive Terminologie, also Termini, die nicht im Textkorpus vorkommen und entsprechend im Unternehmen nicht verwendet werden. Da meist eine große Skepsis besteht, einmal angelegte Daten zu löschen, empfiehlt sich im ersten Schritt eine Kennzeichnung der Termini oder Einträge als „inaktiv“. Dies ermöglicht die getrennte Anzeige und ein gezieltes Filtern von aktivem und inaktivem Bestand. Sollte ein Terminus dann doch verwendet werden, kann er durch Entfernen der Kennzeichnung reaktiviert werden. Nach einem definierten Zeitraum können und sollten inaktive Einträge dann aber endgültig gelöscht werden.
Stufe 2: Strukturbereinigung für eindeutige Informationszuordnung
Die Struktur einer Terminologiedatenbank muss für jede Information einen eindeutigen Ort bieten. Dabei wird zwischen Eintrags-, Sprach- und Terminusebene unterschieden, auf denen Felder und Informationen angelegt werden.
Prüfkriterien für die Struktur können zum Beispiel folgende sein:
- Vollständigkeit: Existiert für jede benötigte Information ein passendes Feld?
- Eindeutigkeit: Ist klar, welche Information in welches Feld gehört?
- Ebenen-Zuordnung: Sind Felder auf der korrekten Ebene angelegt?
- Datenkategorien: Sind die richtigen Feldtypen gewählt (Freitext, Auswahlliste, Multimedia)?
- Benennung: Sind Feldnamen eindeutig und verständlich?
Ein Beispiel aus der Praxis: Ein Feld „Verwendung“ mit den Werten „bevorzugt“ und „freigegeben“ vermischt zwei unterschiedliche Informationstypen, da sich „freigegeben“ auf den Freigabestatus eines Terminus und nicht auf seine Verwendung bezieht. Als Lösung wird ein weiteres Feld „Freigabestatus“ mit entsprechenden Auswahlwerten (freigegeben, zu prüfen) benötigt.
Stufe 3: Metadatenbereinigung für nachvollziehbare Inhalte
Nach der strukturellen Bereinigung folgt die Überprüfung der Metadaten – also der konkreten Inhalte der Felder. Gemäß DIN ISO 26162-1:2020-05 ist die richtige Wahl der Datenkategorie entscheidend für eine sinnvolle Nutzung.
Dabei sollten Sie Freitextfelder nur dort einsetzen, wo variable Inhalte wie Definitionen, Kommentare oder Kontextsätze erfasst werden. Für alle Felder mit einer begrenzten Anzahl möglicher Werte – etwa Verwendung oder Fachgebiete – sind Auswahllisten die bessere Wahl, da sie Schreibvarianten und Wildwuchs verhindern. Multimedia-Felder ermöglichen die Einbindung von Abbildungen, Videos oder Audiodateien, während Ja/Nein-Felder sich für binäre Werte eignen.
Die Bereinigung der Metadaten verbessert nicht nur die Auffindbarkeit und Nachvollziehbarkeit, sondern wirkt sich auch positiv auf nachgelagerte Prozesse aus. Besonders die Glossarerstellung für maschinelle Übersetzung profitiert beispielsweise von eindeutigen Verwendungsinformationen.
Stufe 4: Formale Bereinigung für technische Konsistenz
Formale Aspekte mögen wie Kleinigkeiten erscheinen, summieren sich aber bei der Nutzung in Autorenunterstützungen oder Übersetzungstools schnell zu erheblichem Korrekturaufwand. Typische formale Bereinigungsbedarfe umfassen etwa:
- Groß- und Kleinschreibung
- Verwendung von Pluralformen
- Sonderschreibweisen (z. B. Kapitälchen)
- Klammereinschübe innerhalb von Benennungen
- Bindestrichverwendung
- Leerzeichen und Sonderzeichen
Da es sich bei formalen Bereinigungsaspekten um eine begrenzte Anzahl von Fehlerquellen handelt, lässt sich die Prüfung gut systematisieren. Filter innerhalb der Datenbank können dabei helfen, betroffene Einträge schnell zu identifizieren. Die Korrektur selbst kann meist stapelweise erfolgen – also für viele Einträge gleichzeitig statt einzeln. Einige Bereinigungsschritte lassen sich sogar über mehrere Sprachen hinweg in einem Durchgang durchführen. Für eine Korrektur von Groß- und Kleinschreibungen eignen sich unter anderem Excel-Formeln, wodurch manuelle Korrekturen vermieden werden. Für unternehmensspezifische Besonderheiten und eine schnelle Übersicht des Bereinigungsbedarfs bieten sich Skripte an, die jederzeit erweitert werden können und auch bei umfangreichen Beständen schnelle Ergebnisse liefern.
Stufe 5: Inhaltliche Bereinigung für begriffliche Klarheit
Die inhaltliche Bereinigung bewegt sich häufig im Grenzbereich zwischen formalen und semantischen Aspekten. Während beispielsweise einheitliche Bindestrichregeln nach Produktnamen eher formal sind, erfordert die Entscheidung über Bindestrichschreibung bei Lehnwörtern inhaltliche Überlegungen.
Ein zentraler Aspekt der inhaltlichen Bereinigung ist die Konsistenzprüfung. Alle Termini mit gleichen Wortbestandteilen sollten einheitlich geschrieben und verwendet werden. Häufig entsteht aus dieser Prüfung eine Liste mit unterschiedlichen Schreibweisen, die anschließend vereinheitlicht werden müssen. Auch die Identifizierung von Synonymen und das Festlegen einer Vorzugsbenennung gehören zur inhaltlichen Bereinigung.
Ein wichtiges Werkzeug dabei ist die Dublettenprüfung. Sie zeigt mehrfache Vorkommnisse innerhalb einer Sprache und hilft zu entscheiden, ob es sich tatsächlich um unterschiedliche Begriffe handelt oder ob Einträge zusammengeführt werden müssen. Bei mehrsprachigen Beständen deckt eine Dublettenprüfung in den Fremdsprachen auf, wo in der Ausgangssprache Synonyme existieren oder wo in den Fremdsprachen notwendige Differenzierungen fehlen.
Messbare Erfolge: Der Nutzen sauberer Terminologie
Die systematische Bereinigung von Terminologiedaten zeigt sich schnell in konkreten Verbesserungen. Effizienz, Qualität und Kosten können dabei optimiert werden.
Im Bereich der Effizienzsteigerung profitieren Sie von deutlich reduzierten Suchzeiten für Übersetzer:innen und Autor:innen. Neue Mitarbeiter:innen können sich schneller einarbeiten, und der Abstimmungsbedarf mit zeitraubenden Rückfragen sinkt spürbar.
Die Qualitätsverbesserung macht sich durch konsistente Terminologie über alle Dokumente bemerkbar. Die Fehlerquote in Übersetzungen reduziert sich und besonders die Ergebnisse maschineller Übersetzung (MT) verbessern sich deutlich.
Diese Optimierungen führen zu messbaren Kosteneinsparungen: Weniger Korrekturschleifen bedeuten weniger Aufwand, optimierte MTPE-Prozesse (Machine Translation + Post-Editing) reduzieren die Nachbearbeitungszeit und der laufende Pflegeaufwand der Datenbank sinkt erheblich.
Besonders im Kontext moderner Übersetzungsworkflows macht sich die Investition in saubere Terminologie bezahlt. Die Integration in Systeme wie unsere oneSuite ermöglicht es, das volle Potenzial bereinigter Terminologie für konsistente, effiziente Übersetzungsprozesse zu nutzen.
Fazit: Investition mit hohem Benefit
Die Bereinigung von Terminologiedaten ist eine Investition, die sich messbar auszahlt. Durch eine strukturierte Herangehensweise über die beschriebenen fünf Stufen – Menge, Struktur, Metadaten, Formales und Inhalt – wird aus der komplexen Aufgabe ein überschaubarer Prozess.
Dieser sorgt für spürbare Effizienzgewinne: Schnelleres Arbeiten, weniger Abstimmungsschleifen und bessere Übersetzungsqualität – egal ob human oder maschinell. Eine saubere Terminologie bedeutet also konkrete Kosteneinsparungen bei gleichzeitig konsistenterer Qualität der Unternehmenskommunikation. Gepflegte Terminologiedaten erfüllen damit ihre Schlüsselposition im Unternehmen – und ihre Bereinigung ist eine gewinnbringende Investition.
Sie möchten das Potenzial Ihrer Terminologiedatenbank voll ausschöpfen?
Unsere Expert:innen bei oneword führen gerne eine professionelle Bestandsanalyse durch oder analysieren mit unserem Service oneCleanup das Bereinigungspotenzial Ihrer Datenbank. Nehmen Sie noch heute Kontakt mit uns auf.
8 gute Gründe für oneword.
Erfahren Sie mehr über unsere Kompetenzen und was uns von klassischen Übersetzungsagenturen unterscheidet.
Wir liefern Ihnen 8 gute Gründe und noch viele weitere Argumente, warum eine Zusammenarbeit mit uns erfolgreich ist.