30.09.2025
Vom Datenchaos zum Sprachschatz: Translation Memorys pflegen
Translation Memorys können schnell und unübersichtlich wachsen. Gleichzeitig sind sie ein wahrer Schatz, um Übersetzungskosten zu sparen, Konsistenz sicherzustellen und KI-Systeme zu trainieren. Umso wichtiger ist es, dass Translation-Memory-Daten regelmäßig überprüft, bereinigt und gepflegt werden, damit nicht nur Einsparpotenziale aufgedeckt werden, sondern Ihre Sprachdaten auch fit für KI-Anwendungen sind.
Eine Inventur bringt Licht in den Datendschungel
Translation Memorys (TM) bestehen aus Segmentpaaren, in denen ein ausgangssprachliches Segment einer zielsprachlichen Entsprechung zugeordnet ist. Die Anzahl dieser Segmentpaare – auch Translation Units genannt – können einige Unternehmen vielleicht „Pi mal Daumen“ angeben, für die meisten dürfte sie aber eine komplette Blackbox sein. Dabei handelt es sich bei TMs um wertvolle Sprachdaten, die aktuell etwa für das Training oder die Anreicherung von KI-Systemen in den Fokus rücken. Für eine sinnvolle Nutzung ist allerdings die Qualität der TMs entscheidend, über die häufig genauso wenig bekannt ist wie über ihre Größe.
Denn mit jedem Übersetzungsprojekt kommen Hunderte oder Tausende neue Segmentpaare hinzu. Und während die Wachstumskurve meist nur nach oben zeigt, findet selten bis nie eine systematische Prüfung oder Bereinigung der Daten statt. Was über Jahre als vermeintlicher Wissensschatz aufgebaut wurde, entwickelt sich somit schleichend zur unübersichtlichen Datenhalde.
Diese Intransparenz wird besonders brisant, wenn die Sprachdaten für weitere Prozesse wie Wissensdatenbanken oder KI-Übersetzungen genutzt werden sollen. Denn gerade KI-Systeme benötigen saubere, konsistente Trainingsdaten. Was Übersetzer:innen bei der Übersetzung noch durch Erfahrung und Kontext kompensieren können, führt bei automatisierten Prozessen zu fehlerhaften Ergebnissen. Eine professionelle Bestandsaufnahme Ihrer TMs ist daher keine akademische Übung, sondern eine wirtschaftliche Notwendigkeit. Sie schafft die Grundlage für effizientere Übersetzungsprozesse und erschließt neue technologische Möglichkeiten.
Hauptgründe für unsaubere Translation-Memory-Daten
Trotz des kontinuierlichen TM-Wachstums haben die wenigsten Unternehmen eine Prüf- oder Bereinigungsroutine etabliert, auch weil sie oftmals gar keinen Zugriff auf von Übersetzer:innen oder Dienstleistern verwaltete TMs haben. Neben der großen Datenmenge und der fehlenden Routine gibt es weitere Gründe für unsaubere Translation Memorys.
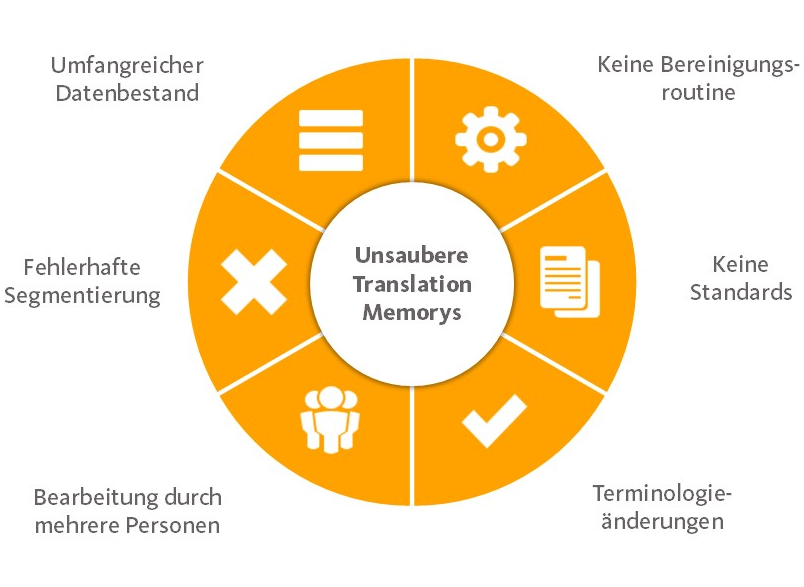
Abbildung 1: Sechs Hauptgründe für unsaubere Translation-Memory-Daten. (Quelle: oneword GmbH)
Gerade wenn Übersetzungen aus unterschiedlichen Quellen – zum Beispiel von unterschiedlichen Dienstleistern – stammen, können Metadaten, Stil oder Qualität uneinheitlich sein. Wenn dann noch Standards für die Systemeinstellungen fehlen, beispielsweise zum Umgang mit Tags und Placeables, oder die Übersetzungen aus unterschiedlichen CAT-Tools stammen, ist der Datenwildwuchs vorprogrammiert. Auch die korrekte Segmentierung spielt eine wichtige Rolle, für die sowohl die Qualität der Ausgangstexte als auch die Segmentierungsregeln im CAT-Tool entscheidend sind. Wird ein Satz zum Beispiel layoutbedingt umgebrochen, entstehen daraus zwei Übersetzungssegmente, die sich wie im folgenden Beispiel in Ausgangs- und Zielsprache nicht mehr entsprechen. Solche Fragmente können ein Übersetzungsrisiko darstellen oder für die Wiederverwendung wertlos sein.
Abbildung 2: Fehlerhafter Umbruch innerhalb eines Satzes und falsche Zuordnung der Segmentteile zwischen Ausgangs- und Zielsprache. (Quelle: oneword Gmbh)
Gespeicherte Übersetzungen sind nur dann wirklich wertvoll, wenn sie nicht nur formal, sondern auch inhaltlich „sauber“ sind. Dabei kommt es auch auf die korrekte Verwendung von Fachtermini an. Jegliche Terminologiefestlegungen oder Änderungen an bestehender Terminologie ziehen dementsprechend Korrekturbedarf in TMs nach sich, der aber selten mitgedacht und umgesetzt wird.
Nachdem die Gründe für ein entstandenes Chaos benannt sind, gilt es, die gewünschte Ordnung in das Datenchaos zu bringen. Dafür sind konkrete Ansatzpunkte entscheidend, die Aufschluss darüber geben, was alles in TMs geprüft und bereinigt werden kann.
Dubletten als Kostentreiber
Von allen Problemen in Translation Memorys verursachen Dubletten die am einfachsten vermeidbaren Kosten. Dubletten entstehen oft schleichend und unbemerkt, zum Beispiel beim Zusammenführen verschiedener TM-Bestände, durch paralleles Arbeiten mehrerer Teams an derselben Datenbank oder durch Tool-Einstellungen, die bei Änderungen neue Einträge anlegen, statt bestehende zu überschreiben. Doppelte Einträge sind allerdings nicht nur überflüssig, sondern können eine echte Kostenfalle darstellen.
Denn je nach CAT-System erhalten sie einen prozentualen Abzug in der Trefferquote, da keine eindeutige Zuordnung zwischen Ausgangs- und Zielsegment möglich ist. Bei einem Wiedervorkommen gelten sie also nicht als volle TM-Treffer, sondern als unscharfe Treffer, sogenannte Fuzzy Matches. Dazu ein Rechenbeispiel: Ein Satz mit zehn Wörtern kostet bei der Neuübersetzung ins Englische exemplarisch 2 €. In einem Folgeprojekt könnte dieser Satz entweder als Full Match komplett gesperrt und damit nicht berechnet werden. Soll er aber erneut überprüft werden, würde er vergünstigt mit nur 67 Cent berechnet. Kommt der Satz allerdings als Dublette im TM vor, wird er systemseitig um 1 % abgestuft und als Fuzzy Match behandelt. Die Berechnung erfolgt dann mit 1,34 € und ist damit doppelt so teuer wie ein Full Match. Hochgerechnet auf Tausende Segmente in einem Übersetzungsprojekt können Dubletten also zu deutlichen und komplett überflüssigen Kosten führen.
Dubletten können in TMs in drei Formen vorkommen: mit komplett identischem Ausgangs- und Zielsegment, mit identischem Zielsegment für unterschiedliche Ausgangstexte oder mit unterschiedlichen Übersetzungen für ein identisches Ausgangssegment. Letztere stellen während der Übersetzung einen zusätzlichen Zeitfaktor dar, da beide Optionen geprüft werden müssen, um eine auszuwählen. Die Bereinigung von Dubletten stellt damit sowohl hinsichtlich ihres Einflusses auf Zeit und Kosten als auch hinsichtlich des Aufwands einen idealen ersten Schritt der TM-Bereinigung dar, da Dubletten schnell gefunden und teilautomatisiert bereinigt werden können.
Bruchstücke in der Datenbank
Übersetzungseinheiten können jedoch nicht nur mehrfach, sondern auch unvollständig im TM enthalten sein. Was als Segment gespeichert wird, hängt maßgeblich von der (vor)eingestellten Segmentierung ab. Üblicherweise markieren Satzendzeichen wie ein Punkt oder Fragezeichen ein Segmentende. Für diese und alle weiteren Satzzeichen wie Doppelpunkte lassen sich aber auch individuelle Segmentierungsregeln definieren. Grundsätzlich sollte ein Segment immer eine vollständige Einheit darstellen, um optimal wiederverwendet werden zu können. In vielen TMs finden sich aber bruchstückhafte Segmente, die zum Beispiel aufgrund manueller Umbrüche fragmentiert wurden.
Ein zusammengehörender Satz wird dann in mehrere Segmente geteilt, wodurch im schlimmsten Fall eine fehlerhafte Zuordnung zwischen den Sprachen erfolgt (siehe Abbildung 2). Eine TM-Bereinigung muss also auch bei fragmentierten Segmenten ansetzen, um sie entweder zusammenzufügen oder zu löschen. Ein Anhaltspunkt für das Auffinden solcher Fragmente können das Fehlen eines Satzendzeichens oder das Vorkommen eines Kommas am Segmentende sein.
Wertlos für die Wiederverwendung
In jeder Datenbank gibt es außerdem Segmente, die zwar singulär und vollständig sind, aber aufgrund ihres Inhalts nicht wiederverwendet werden. Dazu zählen einmalige Pressemitteilungen, Sondernewsletter oder Texte über abgekündigte Produkte. Solche Übersetzungen sollten im besten Fall schon bei der Entstehung nicht in den Übersetzungsspeicher übernommen werden. Bei bereits vorhandenen TM-Daten kann es hilfreich sein, nach alten Produktnamen zu suchen und darüber das Erstellungsdatum eines Textes herauszufinden. Weitere Segmente dieses Datums – möglichst exakt mit der Uhrzeit, da an einem Tag oft mehrere Projekte im Speicher landen – lassen sich dann gezielt herausfiltern und löschen.
Die letzten Schritte auf dem Weg zum Sprachschatz
Wie grundsätzlich mit allen Daten, lässt sich auch mit TM-Segmenten am besten arbeiten, wenn sie sowohl formal als auch inhaltlich sauber sind. Beispiele für formal unsaubere Daten sind Tagfehler oder Segmentpaare mit unterschiedlichen Satzendzeichen pro Sprache. Auch eine falsche Ausgangs- oder Zielsprache, die aus mehrsprachigen Anleitungen versehentlich im TM gelandet ist, zählt zu dieser Kategorie. In vielen TMs finden sich außerdem unübersetzte oder als leer geltende Segmente, in denen statt eines Textes nur ein Punkt oder Sonderzeichen steht. Zu den inhaltlich unsauberen Daten zählen alle Segmente mit sprachlichen, inhaltlichen oder terminologischen Fehlern. Dazu gehören Rechtschreib- und Grammatikfehler genauso wie falsch oder nicht verwendete Fachtermini oder inhaltliche Mängel in der Ausgangs- oder Zielsprache. Die Prüfung und Bereinigung dieser Fehler erfordert sicherlich den größten Aufwand und bedarf entsprechender Sprachkenntnisse.
Die passende Bereinigungsmethode
Um den Aufwand pro Bereinigungskriterium möglichst gering zu halten, bieten sich unterschiedliche Methoden bei der TM-Bereinigung an: Innerhalb von CAT-Tools – also dort, wo die TM-Segmente entstehen – können sowohl verschiedene Einstellungen als auch gezielte Features genutzt werden. In den Einstellungen lässt sich festlegen, welche Metadaten (z. B. Projektname oder Abteilung) zum Segment gespeichert werden und ob bestehende Matches nach einer Bearbeitung überschrieben oder als Dublette angelegt werden. Features zur TM-Pflege – wie die Suche nach Dubletten – und umfangreiche Filtermöglichkeiten innerhalb der Tools ermöglichen einen einfachen Einstieg in die TM-Bereinigung. Beispielsweise kann das standardmäßig gespeicherte Erstellungsdatum eines Segments genutzt werden, um alle Segmente eines bestimmten Projekts herauszufiltern.
Jedes CAT-Tool bietet außerdem die Option, das Translation Memory in Formate wie .tmx oder .csv zu exportieren. Die Exportformate können anschließend in Texteditoren oder Tabellenprogrammen durchsucht, gefiltert und bearbeitet werden. Bei sehr großen Datenmengen empfiehlt sich wiederum der Einsatz von Skripten, die Bereinigungskriterien automatisiert prüfen und umsetzen. Neben dem Know-how über Sprachdaten erfordert diese Methode allerdings entsprechende Programmierkenntnisse.
Datenwachstum in Translation Memory und Terminologiedatenbank bewältigen
Sprachdatenbereinigung leicht gemacht: Mit unserem Service oneCleanup bündeln wir jahrzehntelanges Sprach- und Technologie-Know-how, um aus Ihrem Datenchaos einen wertvollen Sprachschatz zu machen. oneCleanup ist unser Rundum-Service für die Kontrolle, Pflege und Bereinigung Ihrer TM- und Terminologiedaten jeder Größe. Wir analysieren Ihre Daten und liefern Ihnen eine Übersicht über potenzielle Bereinigungsziele wie Dubletten und unvollständige Daten. Was davon umgesetzt wird und ob wir nach der Analyse auch gleich die Bereinigung übernehmen sollen, entscheiden Sie!
Saubere Daten für die KI-Zukunft
Die Bedeutung sauberer Translation Memorys reicht heute weit über die klassische Übersetzungsarbeit hinaus. Denn: Die Qualität von Sprachdaten bestimmt auch maßgeblich den Erfolg Ihrer KI-Initiativen. Unternehmen, die ihre Translation Memorys als echte Assets begreifen und entsprechend kuratieren, verschaffen sich einen nachhaltigen Wettbewerbsvorteil. Sie steigern nicht nur die Effizienz ihrer aktuellen Übersetzungsprozesse und reduzieren Kosten, sondern investieren gleichzeitig in einen wertvollen Datenschatz, der als mehrsprachiges Trainings- und Referenzmaterial für Large Language Models und unternehmenseigene KI-Lösungen genutzt werden kann.
Sie möchten das Potenzial Ihrer Translation Memorys voll ausschöpfen? Unsere Expert:innen bei oneword analysieren Ihre Sprachdaten, identifizieren Einsparpotenziale und entwickeln gemeinsam mit Ihnen eine maßgeschneiderte Bereinigungsstrategie. Kontaktieren Sie uns gerne für ein unverbindliches Beratungsgespräch oder erfahren Sie mehr über unsere TM-Bereinigungsservices.
8 gute Gründe für oneword.
Erfahren Sie mehr über unsere Kompetenzen und was uns von klassischen Übersetzungsagenturen unterscheidet.
Wir liefern Ihnen 8 gute Gründe und noch viele weitere Argumente, warum eine Zusammenarbeit mit uns erfolgreich ist.