Maschinelle Übersetzung
28.09.2022
Fehlerquellen der maschinellen Übersetzung: Wie der Algorithmus ungewollte Rollenbilder reproduziert
Lehrkräfte an Grundschulen sind weiblich, an Universitäten männlich. In Krankenhäusern ist das pflegende Personal weiblich, das ärztliche männlich. Frauen sind hübsch, Männer erfolgreich. Und deutsche Regierungsverantwortliche sind weiblich, auch wenn sie Olaf heißen. Welcome to the machine.
Die Erfolgsgeschichte neuronaler maschineller Übersetzung (NMT) ist zwar erst wenige Jahre alt, aber aus dem Alltag vieler nicht mehr wegzudenken – und sie ist beeindruckend. Ebenso beeindruckend sind oft die Ergebnisse der Maschinen: Übersetzungen lesen sich in vielen Sprachen flüssig und schlüssig und kommen sprachlich korrekt und idiomatisch daher. Doch sprachliche Korrektheit ist nicht gleich inhaltliche Korrektheit und schon gar nicht politische Korrektheit. Denn wer auf maschinelle Übersetzung (MT) setzt, kann immer auch Gefahr laufen, über tradierte Rollenbilder, Stereotype und Gender Bias zu stolpern. Dass man dabei immer Überraschungen erleben kann, zeigen die folgenden Beispiele.
Eine männliche Bundeskanzlerin?
16 Jahre sind eine lange Zeit. Und eine Menge Daten. Vor 16 Jahren brauchte die Bezeichnung „Bundeskanzler“ im Deutschen erstmals eine weibliche Form. Mittlerweile hat sich die politische Landschaft geändert und trotzdem wurde ein Tweet, der den Besuch von Olaf Scholz beim spanischen Regierungschef Pedro Sánchez ankündigte, von der Twitter-eigenen Übersetzungsfunktion mit „Bundeskanzlerin“ Olaf Scholz wiedergegeben:

Fast wähnt man sich zurück in Zeiten, in denen maschinelle Übersetzung eher mit Ausrutschern wie „Gott speichere die Königin“ belustigte. (Dass sich Großbritannien nach siebzigjähriger Regentschaft der Queen nun an einen König gewöhnen muss, ist ein anderes Thema.) Seitdem haben die Maschinen einen Quantensprung gemacht und überzeugen mittlerweile mit flüssigen und idiomatischen Ergebnissen. Wie also kann es immer noch zu einem Ausrutscher wie diesem kommen?
„Das haben wir schon immer so gemacht!“
Die altbekannte Ausrede gegen jede Form von Veränderung und Innovation passt durchaus auch als Erklärung für viele Fehler der MT. Denn 16 Jahre Merkel-Ära sind quasi „schon immer“, wenn es um neuronale maschinelle Übersetzung geht. DeepL zum Beispiel ging 2017, Google Translate 2006 auf den Markt. Beide Systeme haben entsprechend in Millionen von Datensätzen gelernt, dass Deutschland eine Bundeskanzlerin hat. Und auch wenn im Spanischen die männliche Form „canciller“ verwendet wird, sorgen der Kontext und das zugrundeliegende Trainingsmaterial der MT dafür, dass hier das Erwartbare ergänzt wird, anstatt das Dastehende zu übersetzen. Zum gleichen Ergebnis kommt man daher auch, wenn die Bezeichnung alleinstehend übersetzt wird:

Der Fehler bei der Tweet-Übersetzung wird allerdings noch durch die Verwendung von Platzhaltern statt Namen unterstützt: Olaf Scholz ist nicht ausgeschrieben, sondern mit dessen Twitter-Account verlinkt. Sobald der Name als solcher im Text steht, erkennen die MT-Systeme den männlichen Vornamen als Kontext innerhalb des Satzes und ändern die Übersetzung korrekt zu „Bundeskanzler“.
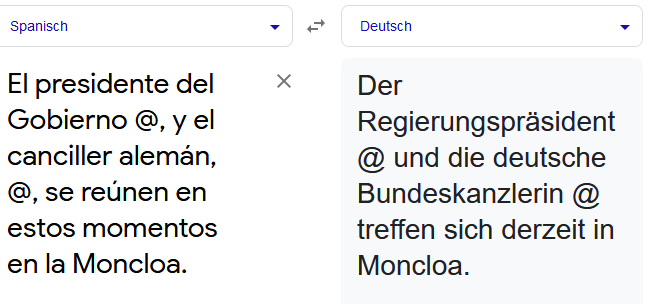
Verwendung von Platzhaltern statt Namen
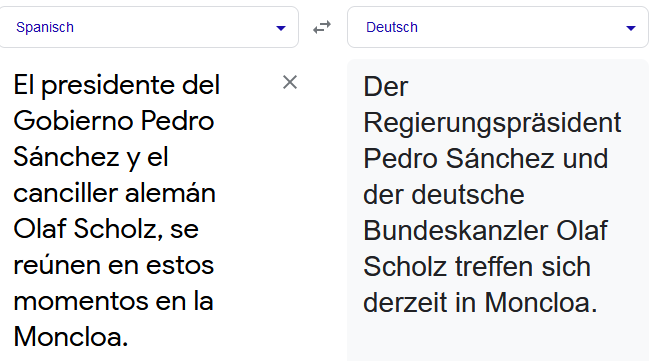
Verwendung der vollständigen Namen
Apropos Kontext: Auch wenn Bezüge innerhalb eines Satzes bei Fließtext mittlerweile sehr gut von den Maschinen erkannt und wiedergegeben werden, bergen Bezüge über Satzgrenzen hinaus ein hohes Fehlerpotenzial. Oder anders gesagt: Die Maschinen erkennen Kontext nur bis zum Satzende. Ein gutes Beispiel dafür:
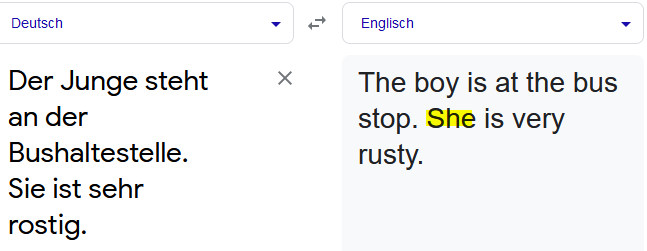
Der Bezug „sie“ im zweiten Satz wird durch die maschinelle Übersetzung auf eine weibliche Person bezogen, anstatt auf die Bushaltestelle (im Englischen sächlich: „it“) aus dem vorhergehenden Satz. Schuld an den fehlenden Bezügen ist oft die Einteilung der zu übersetzenden Texte in einzelne Segmente und die Betrachtung jedes einzelnen Segments als individuelle Einheit. Und selbst bei einzelnen Sätzen kann es einen großen Unterschied im MT-Output machen, ob die Sätze nacheinander oder gleichzeitig mit weiteren Sätzen an das System übermittelt werden.
Was Geschlechtsbezüge mit Rollenmustern zu tun haben
Doch nicht nur der Bezug über Satzgrenzen hinweg ist in der maschinellen Umsetzung fehleranfällig, sondern auch der Bezug auf Personen. Im vorgenannten Beispiel ist „sie“ geschlechtsspezifisch und wird von der Maschine daher mit „she“ übersetzt. Einigen Sprachen fehlt diese Geschlechtsspezifik jedoch komplett, sodass Aussagen geschlechtsneutral formuliert werden können.
Was passiert aber, wenn eine geschlechtsneutrale Aussage in eine Sprache übersetzt werden soll, die Geschlechtsspezifik benötigt? Naheliegend wäre, dass wie beim Gendern einfach immer das generische Maskulinum verwendet wird.
Leider zeigen sowohl Tests als auch die Praxis, dass in diesen Fällen oft ein Gender Bias entsteht, also ein geschlechtsbezogener Verzerrungseffekt. Eigenschaften, Jobs und Tätigkeiten werden von der Maschine auf Basis des zugrundeliegenden Trainingsmaterials übersetzt, das oft das Ausmaß klassischer Rollenbilder und Stereotype zeigt. Aus geschlechtsneutralen Berufsbezeichnungen wie „doctor“ und „professor“ im Englischen werden männliche Berufsbezeichnungen im Deutschen. Die ebenso geschlechtsneutrale Berufsbezeichnung „nurse“ wird hingegen mit „Krankenschwester“ wiedergegeben.

Diese Umsetzung erfolgt sogar, wenn man zwischen geschlechtsspezifischen Sprachen wie Deutsch und Spanisch übersetzt und damit innerhalb der Berufsbezeichnung schon eine Vorgabe zum Geschlecht macht. Egal, wie sehr man es also auch triggern will, pflegendes Personal in Krankenhäusern scheint für die maschinelle Übersetzung grundsätzlich weiblich zu sein:

Maschinelle Übersetzung kann dem Image schaden
Da dieser Bias nicht nur Berufsbezeichnungen, sondern je nach Sprache auch Besitzverhältnisse, Tätigkeiten und allgemein Adjektive umfassen kann, lauern in vielen Texten entsprechende Stolperfallen. In jeglicher Kommunikation, besonders aber in der Unternehmenskommunikation gilt es diese natürlich zu umgehen, um Mitarbeiter:innen und Kund:innen nicht vor den Kopf zu stoßen oder an Image einzubüßen. Denn selbst wo zum Beispiel durch Gendern in der Ausgangssprache ein diverses und offenes Selbstverständnis des Unternehmens unterstützt wird, fördert die maschinelle Übersetzung dann ungefiltert tradierte Rollenbilder zutage.
Interessante Ansätze hin zu einer fairen maschinellen Übersetzung gibt es allerdings schon. Etwa die Anwendung Fairslator, die gängige Online-MT-Systeme nutzt und sprachliche Mehrdeutigkeiten im Ausgangstext erkennt. Zu jeder dieser Textstellen stellt das Tool anschließend gezielte Fragen, beispielsweise ob es sich um eine rein männliche, eine rein weibliche oder eine gemischte Gruppe handelt. Bei gemischten Gruppen können Nutzer:innen dann noch auswählen, ob eine generische oder eine gegenderte Form in der Zielsprache verwendet werden soll. Die Anwendung funktioniert also, wie auch eine Humanübersetzung funktionieren würde: Bei Unklarheiten muss nachgefragt werden. Zudem schärft sie mit diesen Fragen auch das Bewusstsein bei Textersteller:innen, eindeutiger zu formulieren, um den Aufwand an Nachfragen von vornherein zu minimieren.
Zwei Dinge lassen sich also zusammenfassen: Erstens, dass künstliche Intelligenz als Gegenstück immer auch den menschlichen Verstand braucht. Bei maschineller Übersetzung erfolgt dies in Form von Posteditor:innen, die den gesamten Output prüfen, korrigieren und bei Unsicherheiten Fragen stellen. Und zweitens: Bundeskanzlerin ist für die MT-Systeme vielleicht einfach ein generisches Femininum und Männer sind „mitgemeint“.
Mehr Details und Einblicke zu diesem Thema liefert Jasmin Nesbigall, unsere Fachleitung MTPE und Terminologiemanagement, in ihrem Vortrag „MT auf Abwegen – Fehlerquellen maschineller Übersetzung im Unternehmenskontext“ am 09.11.2022 um 9 Uhr auf der tekom Jahrestagung.
Weitere typische Fehlerquellen der maschinellen Übersetzung präsentieren wir auch regelmäßig auf LinkedIn in unserer Rubrik „MTFundstück”. Folgen Sie dort einfach unserem Unternehmensprofil.
8 gute Gründe für oneword.
Erfahren Sie mehr über unsere Kompetenzen und was uns von klassischen Übersetzungsagenturen unterscheidet.
Wir liefern Ihnen 8 gute Gründe und noch viele weitere Argumente, warum eine Zusammenarbeit mit uns erfolgreich ist.