23/07/2025
Assessing quality: automated MT evaluation in practice
The use of machine translation has long been established in many companies, but there is often no routine for evaluating quality. It’s worthwhile not only to carry out an initial quality check when choosing a machine translation system, but also to monitor quality continuously to enable you to detect quality changes at an early stage. However, human review of large volumes of machine-translated content in various target languages is neither economically viable nor feasible for most companies in terms of human resources. This is where machine metrics for the automated evaluation of MT systems can help. We explain how they work, what they can do and why humans are still indispensable in the process.
Similarities and differences: quality evaluation and quality estimation
Anyone who has ever been to a new city in search of a potential favourite restaurant knows how difficult such an undertaking can be. Online reviews often provide a first indication and suggest where you can eat well. The search results can also be narrowed down using filter options. And yet many of your own preferences remain unconsidered in the end, so that you still have to try out new restaurants yourself. The evaluation of MT systems is basically very similar: automated metrics give you the first important indications of where you should critically scrutinise the quality of your machine translations. However, they only base their decision on simple general criteria, such as completeness and conformity with a reference in terms of content and form.
In the automated evaluation of MT systems (also known as quality evaluation), a comparison is made between the raw machine translation and a “reference”, i.e. a high-quality checked translation of the same text. This forms the standard to which the machine translation result should approximate. Quality evaluation therefore differs from quality estimation, which evaluates machine translations without using a reference text. Quality estimation is primarily used in the ongoing translation process, where the rating per segment is used as an indicator of which segments require post-editing. How reliable this rating is depends heavily on the quality estimation model used.
Quality evaluation, on the other hand, is used to assess the average quality of an MT system across many translated segments. As it requires a reference translation, it takes place after MTPE projects.
The results of an evaluation can be used to identify measures to improve the raw machine output, for example by adapting the source texts for translation. If the evaluation is applied comparatively to the output of several MT systems, it can also support the decision as to which of the MT systems is better suited to the language and text type in question.
How automated metrics actually work
Online restaurant reviews with enthusiastic 5 out of 5 stars as well as those with only one star arouse curiosity in many of us to find out what this rating is based on. If, for example, the 1-star rating only reflects frustration about the noisy people at the next table, this says little about the quality of the food. If we receive a value of 0.82 on a scale of 0 to 1 when evaluating MT systems, this is also initially a black box. So it’s time to understand what the evaluation is based on.
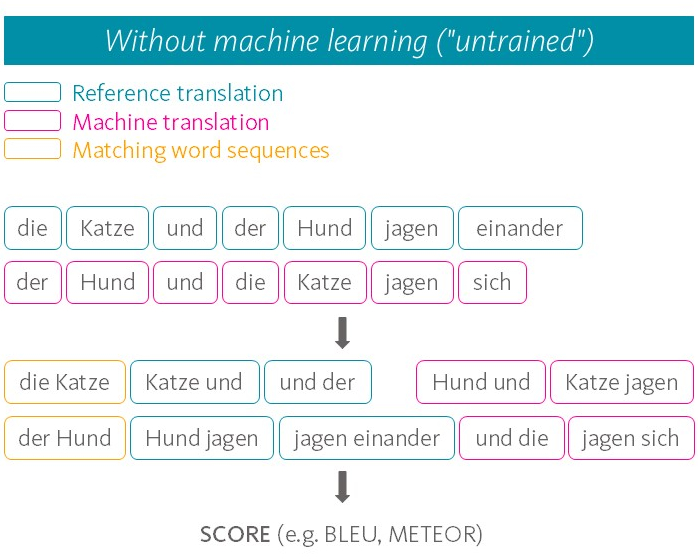
During the automated evaluation, a numerical value is calculated for each segment within the text to indicate how good – i.e. how close to the reference – the machine translation is. In addition, an overall value is obtained from the average of the segment ratings. Only a look at the underlying algorithms provides information on what the segment ratings are made up of and where the limitations of automated evaluation metrics lie. The algorithms used can be roughly divided into two types, depending on whether they process the texts with or without artificial neural language models. Let’s start with the simpler type of evaluation metric, the most popular representative of which is the BLEU metric. It works relatively simply, only dividing a text into its word units and comparing on this basis whether the MT output and the reference translation contain the same words, if possible even in the same order. The greater the match, the better the result. However, the meaning of the individual words and the sentence formed from them are not taken into account. Reformulations using synonyms or a different sentence structure are thus penalised, although such differences between independently produced translations are very common.
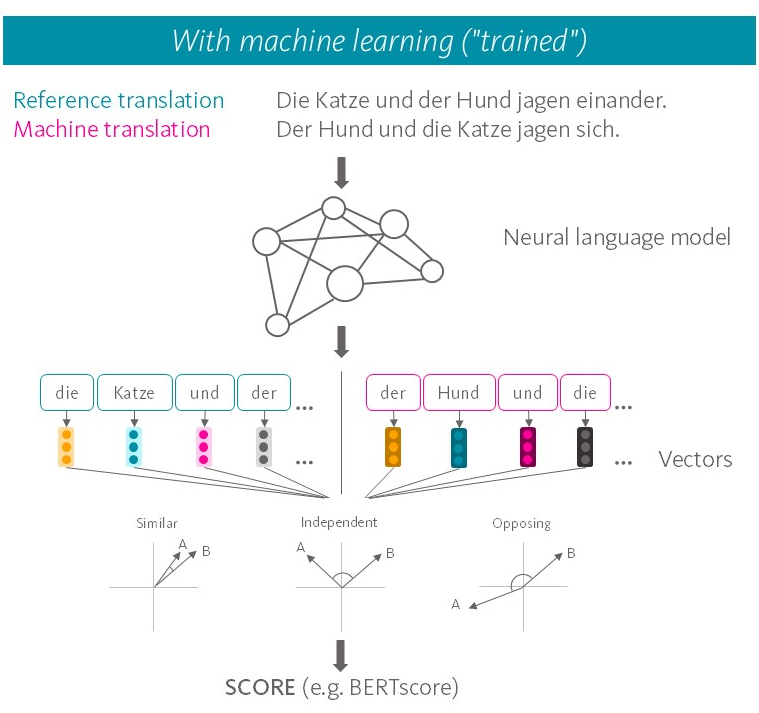
More sophisticated metrics, on the other hand, use artificial neural language models that first convert the text into a numerical representation format, which is then used to compare MT output and reference. This has the advantage that neural language models represent the meaning of words and sentences as multidimensional vectors, which means that similar meanings are reflected in similar vectors. The process thus captures the use of synonyms and variations in sentence structure. To evaluate the MT output, the similarity between the relevant vectors is determined. The greater the similarity, the better the evaluation of the MT output in evaluation metrics such as BERTscore.
The COMET evaluation metric is somewhat more complicated: after the initial processing in the neural language model, it uses a second neural network to evaluate the MT output. This network was trained using human evaluations of machine translations to predict how humans would evaluate the MT output. In this way, COMET is intended to achieve a higher correlation with human assessments of MT output.
To summarise, automated evaluation metrics can reveal differences in content by comparing MT output and a reference translation. Gross deviations, such as omissions and additions, as well as inaccurate translation output, can be recognised by means of the algorithms used. But what about other quality criteria?
Limitations and benefits in practice
At oneword, we deliberately do not rely on fully automated evaluation, but on direct dialogue with the post-editors. Mandatory feedback on the MT output is provided after each MTPE project. This records sources of error in ten categories, such as completeness, spelling and grammar. The results show that while correct spelling, grammar and a complete result are often given, errors often occur in the machine output, especially in terminology, formatting and internal consistency, which make human post-editing essential.
However, one problem with the automated evaluation of MT systems is that terminology and internal consistency in particular are not checked correctly. None of the evaluation metrics are able to take into account an organisation’s specified terminology or usage, as defined in a terminology database or style guide. At most, metrics will register terminology errors as deductions for word differences if a different term was used in the MT output than in the reference translation. Equally critically, as the metrics evaluate at segment level, inconsistencies between segments are completely ignored.
Conclusion: An investment with great benefits
In view of these limitations, it is clear that human evaluation remains essential in order to capture the sometimes subtle factors that make up the quality of a text. Automated evaluations of MT systems should therefore not be used in isolation. Nevertheless, the benefits for better MT output remain enormous. Automated evaluation can provide important initial impressions of the quality of an MT system, particularly when it is applied to large volumes of text that are subsequently analysed on a random basis. The human review, especially of the segments with a particularly positive or negative rating, subsequently provides information about the sources of error in the MT output and the reliability of the evaluation metric. The results can thus support the choice between two MT systems or the decision for or against the use of machine translation in general. So it’s like looking for a good restaurant: nobody knows your own requirements better than you do!
Would you like to have the quality of your MT system professionally assessed? Or are you looking for the optimal combination of automated evaluation and human expertise?
Talk to us – we can help you get the most out of your machine translation and work economically at the same time. With oneSuite and our many years of expertise in machine and AI-supported translation, we work with you to find the best solution for your requirements. Contact us today.
8 good reasons to choose oneword.
Learn more about what we do and what sets us apart from traditional translation agencies.
We explain 8 good reasons and more to choose oneword for a successful partnership.